

[ad_1]
Coaching with automated knowledge pipeline
Voyager builds on Tencent’s earlier HunyuanWorld 1.0, launched in July. Voyager can also be a part of Tencent’s broader “Hunyuan” ecosystem, which incorporates the Hunyuan3D-2 mannequin for text-to-3D technology and the beforehand coated HunyuanVideo for video synthesis.
To coach Voyager, researchers developed software program that mechanically analyzes present movies to course of digicam actions and calculate depth for each body—eliminating the necessity for people to manually label 1000’s of hours of footage. The system processed over 100,000 video clips from each real-world recordings and the aforementioned Unreal Engine renders.
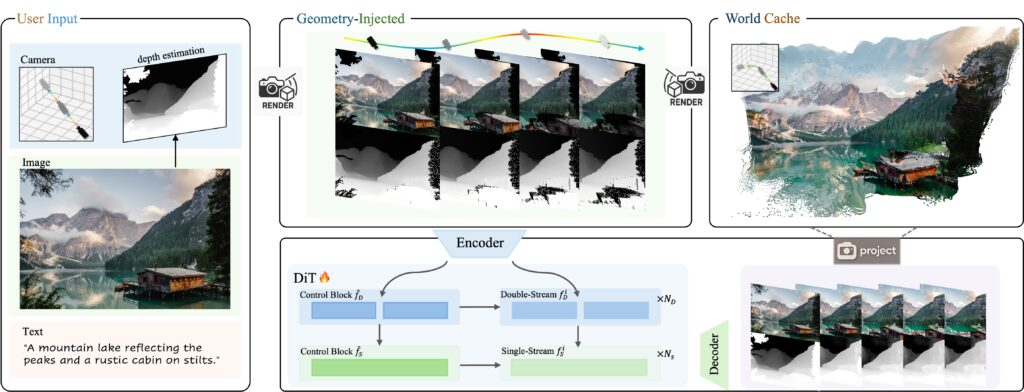
The mannequin calls for severe computing energy to run, requiring not less than 60GB of GPU reminiscence for 540p decision, although Tencent recommends 80GB for higher outcomes. Tencent revealed the mannequin weights on Hugging Face and included code that works with each single and multi-GPU setups.
The mannequin comes with notable licensing restrictions. Like different Hunyuan fashions from Tencent, the license prohibits utilization within the European Union, the UK, and South Korea. Moreover, industrial deployments serving over 100 million month-to-month lively customers require separate licensing from Tencent.
On the WorldScore benchmark developed by Stanford College researchers, Voyager reportedly achieved the very best general rating of 77.62, in comparison with 72.69 for WonderWorld and 62.15 for CogVideoX-I2V. The mannequin reportedly excelled in object management (66.92), fashion consistency (84.89), and subjective high quality (71.09), although it positioned second in digicam management (85.95) behind WonderWorld’s 92.98. WorldScore evaluates world technology approaches throughout a number of standards, together with 3D consistency and content material alignment.
Whereas these self-reported benchmark outcomes appear promising, wider deployment nonetheless faces challenges because of the computational muscle concerned. For builders needing sooner processing, the system helps parallel inference throughout a number of GPUs utilizing the xDiT framework. Operating on eight GPUs delivers processing speeds 6.69 instances sooner than single-GPU setups.
Given the processing energy required and the constraints in producing lengthy, coherent “worlds,” it could be some time earlier than we see real-time interactive experiences utilizing the same approach. However as we have seen to this point with experiments like Google’s Genie, we’re doubtlessly witnessing very early steps into a brand new interactive, generative artwork type.
[ad_2]









